Code
Table of Contents
1. Finding structures in text
In the first example, we use DocumentExtractor's processPlainText() method to process a string. The result is a list of Hit objects that contain:
-
text, the string fragment that was recognized;
-
position, the character index where this text is found;
-
structure, a Molecule instance containing the recognized structure.
...
String test = "Aspirin:" +
"Aspirin is the brandname of acetylsalicylic acid (ASA)." +
"It has many uses, but is most commonly used as a pain killer, " +
"or used to reduce fever or inflammation.";
//process the string and get the results
DocumentExtractor x = new DocumentExtractor();
x.processPlainText(new StringReader(test));
List<Hit> hits = x.getHits();
//print out the recognized names
for (Hit hit : hits) {
System.out.println(hit.structure.getName());
}
...
Resources:
-
Example code: Demo1.java in the zip file
2. Finding structures in a live webpage
In this section, the first example is extended with functionality to download a live webpage and process it using DocumentExtractor's processHTML() method.
Loading a URL is done using the Apache HttpClient, a more basic solution might use the java.net.HttpURLConnection class. The returned string can be passed to DocumentExtractor using a StringReader.
...
private static String loadURL(String url) throws Exception {
HttpClient httpclient = new DefaultHttpClient();
try {
HttpGet httpget = new HttpGet(url);
ResponseHandler<String> responseHandler =
new BasicResponseHandler();
String responseBody = httpclient.execute(
httpget, responseHandler);
return responseBody;
} finally {
httpclient.getConnectionManager().shutdown();
}
}
...
Resources:
-
Example code: Demo2.java and httpclient JAR files in the zip file
3. Finding structures in a PDF document
Document to Structure is able to extract structures from PDF files since version 5.4. This supports only text-based PDF files. If OSRA is installed, graphical repesentations of chemical structures are also processed. To retrieve the text content of a file, Apache PDFBox is used.
In this section, the former example has been modified to process a PDF file.
Instead of passing a Reader with the content to process, the readPDF() static method has to be use to create a DocumentExtractor instance that automatically reads the text from the document. After this, the processPlainText() method is called.
The returned Hit objects contain the page number where the hit was found. This can be accessed with the getPageNumber() method.
...
FileInputStream pdf = null;
try {
pdf = new FileInputStream("test.pdf");
DocumentExtractor x = DocumentExtractor.readPDF(pdf);
x.processPlainText();
List<Hit> hits = x.getHits();
//show where each structure was found
for (Hit hit : hits) {
System.out.println(hit.text +
" found on page " + hit.getPageNumber());
}
} finally {
if (pdf != null) {
pdf.close();
}
}
...
Resources:
-
Example code: Demo3.java and httpclient JAR files in the zip file
4. Highlighting recognized structures in a webpage
A good way to display the results of processing is to show the recognized structures directly in the original document. In HTML pages this can be done by modifying the HTML code around each hit.
Using the position field of the Hits, you can find the recognized names and wrap them with a special element. To keep track the modification in the HTML code, an extra variable (modification) is used.
...
public static String prefix = "<span data-structurename=\"%n\">";
public static String suffix = "</span>";
...
int modification = 0;
for (Hit hit : hits) {
//add the corrected name of this hit to the data attr.
String current_prefix = prefix.replace("%n",
hit.structure.getName());
//add the modified prefix before, and the suffix after this hit
pagecontent = pagecontent.substring(0,
hit.position - 1 + modification) +
current_prefix + hit.text + suffix +
pagecontent.substring(hit.position - 1 +
modification + hit.text.length());
//update the amount of modification performed so far
modification += current_prefix.length() + suffix.length();
}
System.out.println(pagecontent);
...
Highlighting can be achieved by styling the added elements using CSS: for this, a class can be added to the element.
Resources:
-
Example code: Demo4.java and httpclient JAR files in the zip file
5. Saving results in SDF or MRV file format
This example is extended with the functionality that saves the results into a multi-molecule file using the MolExporter class.
Using the Molecule.setProperty() method, you can save related information in data fields such as the hit text, position; or in case of PDF files, you can add the page number.
...
//MolExporter exporter = new MolExporter("test.sdf", "sdf");
MolExporter exporter = new MolExporter("test.mrv", "mrv");
try {
for (Hit hit : hits) {
hit.structure.setProperty("hit text", hit.text);
hit.structure.setProperty("hit position", hit.position);
exporter.write(hit.structure);
}
} finally {
exporter.flush();
exporter.close();
}
...
Resources:
-
Example code: Demo5.java and httpclient JAR files in the zip file
6. Storing results in a JChem structure table
JChem structure tables are fast, scalable and searchable repositories of chemical structures. This example is extended with the functionality to store the hits in a table.
Creating a structure table is detailed in the Administration Guide of JChem. The recommended table type for this example is "Any structure" because some structures returned by DocumentExtractor contain query or R-group features (e.g.: penicillin). It is also recommended to enable the "Filter out duplicate structures" option because a structure usually appears several times in a document.
To store additional information about each structure, add 2 extra columns to the table (Administration Guide):
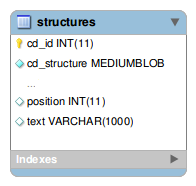
The ConnectionHandler and UpdateHandler classes are used to manage connection and data in the structure table.
Setting up a database connection, to a MySQL database and its structures table:
...
ConnectionHandler database = new ConnectionHandler();
database.setDriver(DatabaseConstants.MYSQL_DRIVER);
database.setUrl("jdbc:mysql://localhost/database");
database.setLoginName("username");
database.setPassword("password");
database.connectToDatabase();
UpdateHandler uh = new UpdateHandler(database,
UpdateHandler.INSERT, "structures", "position, text");
...
Next, you need a function to call while processing the hits. This function takes a Hit and stores it in the structure table.
...
private static void addStructure(Hit hit)
throws SQLException {
String struct = hit.structure.toFormat("mrv");
uh.setStructure(struct);
uh.setValueForAdditionalColumn(1, hit.position, java.sql.Types.INTEGER);
uh.setValueForAdditionalColumn(2, hit.text, java.sql.Types.VARCHAR);
uh.execute();
}
...
Resources:
-
Example code: Demo6.java and httpclient JAR files in the zip file
7. Increasing processing speed by multithreading
Performance is a high priority in online services. The example presents multithreading functionality to take advantage of a common multicore CPU on a single HTML page.
Splitting the HTML document into pieces, each thread can work independently. Splitting points need to be chosen carefully to ensure that possible results are not lost. We can only cut where no structural information would continue, such as at the end of sentences or at section separators.
Using certain HTML elements as separators is a good choice and they are easy to find with regular expressions. Here you can see a pattern that achieves this by cutting at block level HTML and other safe elements.
...
Pattern p = Pattern.compile("(.{2000}.*?</?(a|abbr|blockquote|" +
"caption|code|dd|div|dl|dt|h1|h2|h3|h4|h5|h6|hr|img|label|" +
"legend|li|ol|p|pre|table|td|th|tr|ul)[^>]*>|.*$)",
Pattern.CASE_INSENSITIVE | Pattern.DOTALL);
...
After splitting the content of the page using this pattern, a task is created for each piece - chunk - using the java.util.concurrent framework. A task processes that piece of content similar to the second example.
...
int availableProcessors = Runtime.getRuntime().availableProcessors();
ExecutorService exec = Executors.newFixedThreadPool(availableProcessors);
ExecutorCompletionService execservice = new ExecutorCompletionService(exec);
int execservicesize = 0;
...
Matcher m = p.matcher(pagecontent);
while (m.find()) {
//create and submit new callable instance
execservice.submit(new DocumentExtractorTask(m.group(1)));
execservicesize++;
}
...
while (execservicesize-- > 0) {
//wait until the next fragment is finished
Future<List<Hit>> f = execservice.take();
List<Hit> hits = f.get();
//print out the name of each recognized structure
for (Hit hit : hits) {
System.out.println(hit.text);
}
}
...
This solution works for HTML documents, however, fragmenting pages with other content types is not easy, since traditional separators such as punctuation characters can appear in structure names. If you have a good solution to this problem, please do not hesitate to share it in our forum.
Resources:
-
Example code: Demo7.java and httpclient JAR files in the zip file