Query builder
The query builder panel is is not shown by default, but can be shown using the Window -> Query Builder menu item. It will appear by default in the lower left corner of the IJC window. The query builder allows you to construct more complex queries for execution, including structural and non-structural terms, and apply them to your data tree or other specified domains. A query is built from "query terms" which are described below.
Field Value and Operator - Query Terms
Queries are constructed using the basic units of fields and operators. A query can comprise of a simple condition such as 'MolWeight < 300', but also might include structural search terms either depicted as a chemical structure or in the form of Chemical Terms filters. Fields can be added to the query builder by right click on the query builder panel and select the field(s) to add. New fields are initially added with an AND operator and a change (to OR) here will apply to all fields subsequently defined. It is possible to add new AND/OR in addition to build up different logic to 'all' or 'any'. Once a field is added, you typically select from the available operators (e.g.'<' in the above example) and enter the value(s) ('300' in the above example). Once a suitable value is placed in the field the red cross will convert to a green tick, indicating a valid value is entered for that element of the query.
Querying with Standard Fields
For each standard field present in a table, the field name is displayed along with a drop-down list for defining the query operator (=, <, <=, Between, etc.) as well as one or more elements for specifying the values for the query.
Specify the appropriate operator in the drop-down list and enter the value(s) for the query in text box(es).
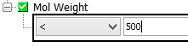
Most operators take a single value. Exceptions are:
-
The BETWEEN operator which provides you with 2 text boxes, the first for the minimum and the second for the maximum value.

-
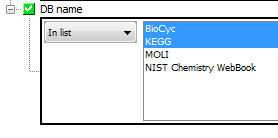
The IN LIST (and NOT IN LIST) operator which requires you to enter a comma separated list of values (e.g. 1,2,4,8,16). Since IJC 5.3.2 "smart paste" has been implemented when the IN LIST operator is specified, which allows easy pasting of values when present in a recognisable format that is not comma separated. This includes copy of a list from the lists and queries window, text format when the values are separated by new line characters, and a column of values from Excel or Open Office.
-
If the field is defined as containing a 'discrete set of values' then those values are presented in a multi-select list allowing you to specify them without typing.
-
If you need to use IN LIST operator to query for multiple values that already contain a comma, you have to define the query with help of double quotes (e.g. "Doe, John", "Smith, Jane").
-
When using Oracle and MySQL database, the result set will be ordered based on the order of items in the query definition, e.g. the search for IDs 20, 5, 35 and 11 will provide hits ordered in the same way. On Derby, the hits will be ordered ascending.
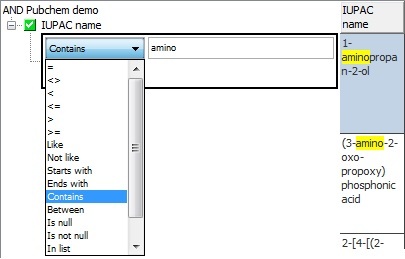
Wildcard searches are possible for text fields using the 'like' operator. Use the appropriate wildcard character for the type of database (usually % for zero or more characters and _ for a single character). For instance 'like amino%' will find all values starting with the term 'amino'. Shortcut operators are provided for some commonly used wildcard searches:
-
'starts with amino' (equivalent to 'like amino%'
-
'ends with amino' (equivalent to 'like %amino'
-
'contains amino' (equivalent to 'like %amino%'
You can search for values that are missing or present using the 'Is null' and 'Is not null' operators. For instance if you use the 'Is null' operator you will fetch all rows for that field that do not have a value defined.
Wildcard searches allow hit highlighting for the text field search with operator like (LIKE, Starts with, Ends with, contains, etc.) . After running query highlight the appropriate part of value in results which was searched in form in text widgets.
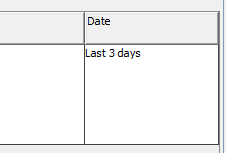
Querying with Date Field
As you can see on the screenshot below, Date field query contains unique query operators.
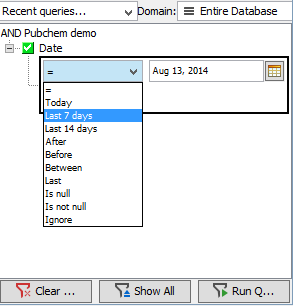
The query supports standard operators (such as 'equals') and in addition to that, it offers the following unique extras:
-
Today - this operator translates as "Last 1 day"
-
Last - this operator will search back for all date fields in a specified range, including "today"
-
Before and After - those operators are equivalent to previously used < and > respectively
The query operators are also supported in the Form Based Query as you can see on the screenshot below
Case Insensitive Text Search
This useful text search option has been introduced in IJC 5.7. All search operators are supported except "Is null" and "Is not null" where it's logically not an option. Text searches are case sensitive by default when using Oracle or Derby. MySQL allows only case insensitive search by now, regardless of the actual setting in the schema/query.
This property must be specified separately at the given text field. There is currently no way how to set it globally for all text fields present in the schema. Settings are controlled at two different levels, permanent and temporary. You can permanently set flag Case Insensitive Search in Extra attributes of a text field in Data trees/Entities editor. Default behaviour is determined by that Extra attribute and it's stored permanently in the schema settings.
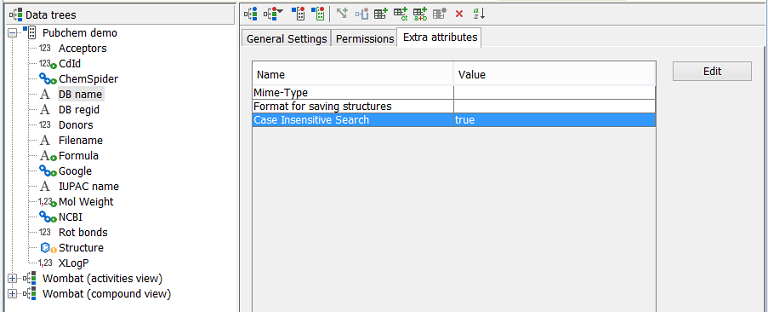
You may want to change it instantly in query builder. Simple thick box is shown at a text field. This is also possible in a form based query where it's accessible in pop-up menu. Query can be combined and for the same field setting of Case Insensitive Search can differ. Current settings will be held in memory until you stay connected to the schema unless the query is cleared.
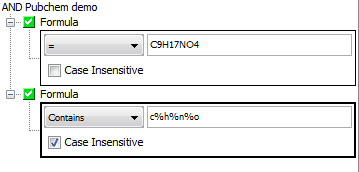
Additionally all query settings can be stored as a permanent (temporary) query. Textual chemical terms field are supported as well.
Querying with Structure Fields
The structure query features of IJC are provided by the Marvin and JChem toolkits. See these links for detailed documentation on these features:
Structure search operators
With structure fields you can specify queries of type:
-
Substructure: The target molecule (graph) contains the specified query structure (graph)
-
Superstructure: The target molecule (graph) is contained within the query structure (graph)
-
Similarity: A measure of how similar the target is to the query, based upon structural fragment fingerprints and as defined by the associated normalised co-efficient
-
Duplicate: The target is identical to query, including things like stereochemistry and isotopes. Note: this type of search used to be referred to as 'Perfect'.
-
Full: The target is identical to query, allowing user to define things like stereochemistry and isotope matching. Note: this type of search used to be referred to as 'Exact'.
-
Full Fragment: as for Exact, but match only has to be for one component of the target (target can contain multiple molecules). Note: this type of search used to be referred to as 'Exact fragment'.
Not all query types are available for every JChem table type

In order to edit the structure of the queried field, double-click the structure panel to open Marvin Sketch.
Check the 'Return non-hits' check box if you want to reverse the meaning of the search e.g. find all the structures that don't match the specified structure query.
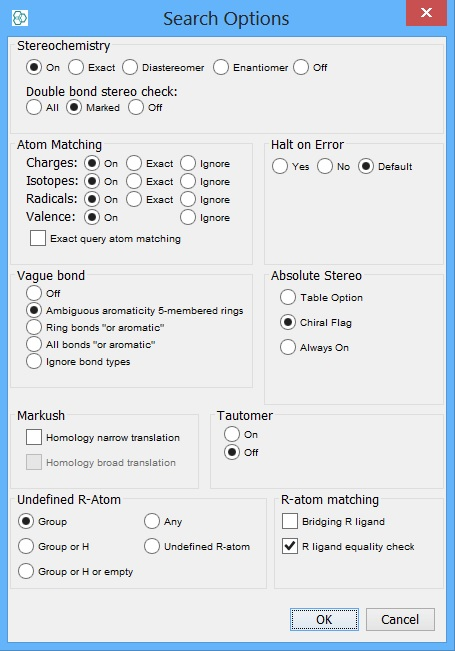
Structure search options
The different types of search operators have different sets of options. Default options are specified and are often OK, but you may want to fine tune how the search executes by specifying different options. To define the options click on the options button (  ) for a dialog that allows you to specify advanced searching settings, such as stereochemistry options and similarity search threshold (floor). Alternatively, once you have selected your search type you can right click and select 'Options'.
) for a dialog that allows you to specify advanced searching settings, such as stereochemistry options and similarity search threshold (floor). Alternatively, once you have selected your search type you can right click and select 'Options'.
Duplicate search options
Duplicate search has a very limited set of options, just those that allow stereochemistry to be turned off and to enable tautomer searching. This will have the effect of return more hits which cover all stereoisomers and tautomeric forms found in the target
Full, Full fragment, Substructure and Superstructure search options
These search types have a wide range of options to control the stereochemistry, atom matching, bond matching and tautomer search options. Please refer to stereo chemistry options and absolute stereo options which describes the option definition and the effect on the query results. Options for searching generic R-groups are described on Group matching of undefined R-atoms which also explains their behaviour. Homology search options are documented in the JChem homology groups subsection for narrow translation and on the Markush structures search page for broad translation.
Halt on Error option defines what will happen if an error in the query or in CT filter query occur. By default search finishes with an error and results are not returned. If you set Halt on Error to no, structures where an error occur are omitted and all other structures which satisfy the query are returned.
See the screen shot below for these options which are the same implementation in IJC.
Similarity search options
Similarity search has quite different options to the other search types. The basic option to specify is the similarity threshold, a number between 0 and 1, where 0 is completely dissimilar and 1 is 100% identical.
In addition to the threshold you can specify a Screening Configuration to use. For normal tables containing molecules the default is Tanimoto distance, but other metrics are available and can be selected from the drop down list. The most interesting of these is Tversky, which has some additional parameters that can be specified. These are entered into the text box. For Tversky two parameters are needed:
-
Query weight: number between 0 and 1
-
Target weight: number between 0 and 1
These are entered as comma separated values as shown in the screen shot below.
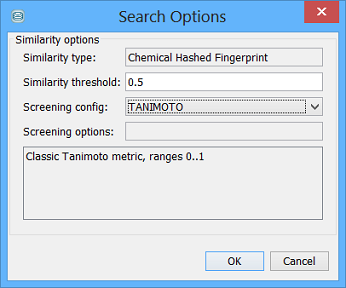
Other metric types either do not have parameters or there parameters are hard coded special cases of Tversky (e.g. DICE is Tversky with query weight and target weight both being equal to 0.5).
The Screening Configuration is specific to the type of structure table. Reaction tables have a different set of metrics which allow the type of similarity to be defined. The options are:
-
Reactant Tanimoto: similarity of the reactants
-
Reactant Tanimoto: similarity of the products
-
Strict reaction Tanimoto
-
Medium reaction Tanimoto
-
Coarse reaction Tanimoto: these last three use similarity of both sides of the reaction but differ in the extent around the reacting centre that is considered (see the documentation for details)
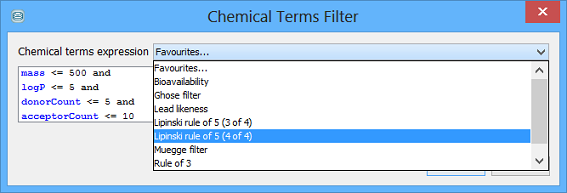
Specifying a Chemical Terms filter
With structures you can also specify a Chemical Terms filter that can be applied to the query. To do this, enter the Chemical Terms expression into the Chemical Terms filter box located beneath the Marvin Sketch panel; alternately, click on the advanced button (  ) to open the Chemical Terms editor which will allow you to enter the expression or use one of the pre-defined favourites. This filter is applied to each result of the search and used as an additional filter for the search results. An example would be to retrieve only structures that have a logP of less that 5 by entering the expression
) to open the Chemical Terms editor which will allow you to enter the expression or use one of the pre-defined favourites. This filter is applied to each result of the search and used as an additional filter for the search results. An example would be to retrieve only structures that have a logP of less that 5 by entering the expression
logP() < 5Chemical Terms filters are applied dynamically to the query results. If you have lots of results the search will be much slower with a Chemical Terms expression as part of the query. If you are frequently using the same Chemical Terms expressions, you should probably generate a Chemical Terms Field in advance, instead so that the values are present in the database and so can be queried directly without being recalculated each time a query is run.
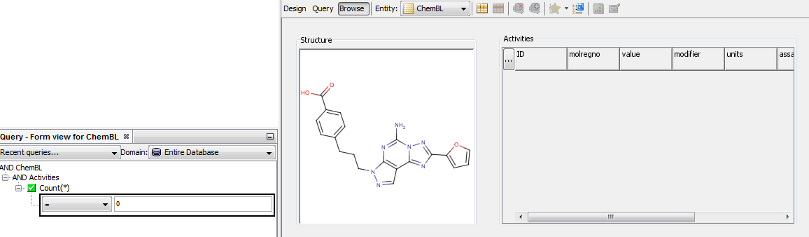
Not exists capability
There is a subtle difference in IJC (and RDBMS in general) between the IS NULL operation and rows which don't exist. In the case of IS NULL, the question asked is to return rows that exist but contain no data for particular field(s). This means the basic join operation does complete successfully, for a given case and the foreign key field value does exist in the child table, displaying some rows, with no apparent values for the field(s) in question. The slightly different case of the 'Not exists' query is such that is facilitates queries described like 'display only parent rows that have no child data' or indeed 'display only parent rows that have X child data'. In IJC, to be able to construct queries of this nature, one should use the available 'COUNT ![]() ' operator. A small example is given next to show this working.
' operator. A small example is given next to show this working.
For example if we have a simple parent (Molecules/Structures) and child (Assay points) in a one to many relationship based upon some primary key (parent unique identifier) and wish to obtain all molecules that are yet to be screened we can assemble a query such as below in the Query builder. You will note that the COUNT ![]() field is only available at the detail level to facilitate this sort of query, it does not make sense at the parent level to retrieve a number of rows without any other criterion defined.
field is only available at the detail level to facilitate this sort of query, it does not make sense at the parent level to retrieve a number of rows without any other criterion defined.
Query term validation
To be executed all elements of the query must be valid (green ticks). When a term is first added to the query it may be in an invalid state because you have not specified the required values.
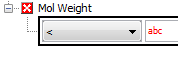
The elements of the query term you can specify depend on the Field type. Typically you will specify the operator and one or more values. Once the terms have been correctly specified the query element will be valid.
Repeat this for all the Fields which you want to include in the complete query. If you wish to exclude a Field from the query set its operator to 'Ignore'.
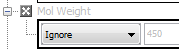
Any part of the query can be collapsed to take up less space. Collapsed elements display a text summary of the current query criteria. Elements that are set to ignore are displayed as collapsed by default.
AND and OR elements
Simple AND/OR query terms
You will notice initially, at the root of the query tree the AND expression is the default and this logic applies to all subsequent fields making the query read like 'all' field/operator conditions must be met. This initial choice can be modified to OR by right click on the query root and select 'change to OR'. If OR was already specified the inverse is visible 'change to AND'. By changing from AND to OR we effectively change from 'all' to 'any condition can be met'. Fields can be easily removed using right click and delete.
Complex relational AND/OR query terms
More complex queries can be constructed than the relatively simple 'any'/OR or 'all'/AND arrangements described above. For example you can construct queries which contain mixtures of nested AND/OR logic by right click on the query root node (or subtree) and then either 'add OR element' or 'add AND element'. The choice available depends upon the existing value set for that node on which you click. These new nodes are considered as sub-trees and you can see this by the Explorer style display which shows the nesting arrangement. You might wish to include fields from different entities in your subtrees to build up more complex queries. Nesting can continue several layers deep and this allows you to build up relational queries where conditions from multiple Entities are used in the query. Subtrees can be easily removed by right click and select 'DELETE subtree'.
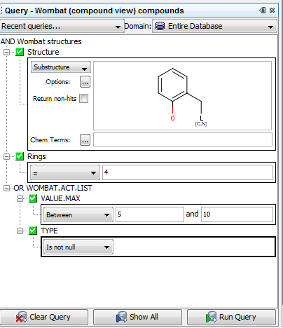
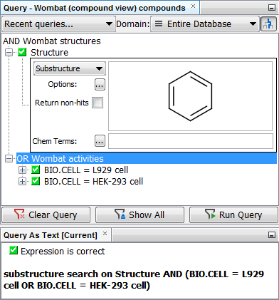
Due to technical limitations, it is not possible to query for two different data entries in one child data table field combined by an AND operator. Such query leads to no results. An example from IJC demo project (Wombat (compound view) data tree is shown below.
TARGET.NAME contains 5-HT2A AND TARGET.NAME contains 5-HT2C However, combining two different data entries in one child data table field can be successfully combined using an OR operator. An example from IJC demo project (Wombat (compound view) data tree is shown below, such query leads to 68 hits.
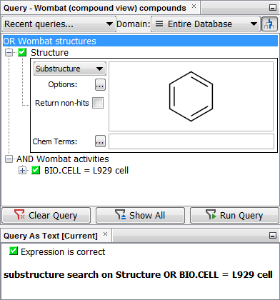
TARGET.NAME contains 5-HT2A OR TARGET.NAME contains 5-HT2CIf there is a need to search for parent data that are linked to both child data, it is possible as a two-step search utilizing the domain search feature described here. It is possible to query using one data entry as the definition and use the result set as a domain for second data entry as the definition in the subsequent query.
Expanding and collapsing query nodes
All the elements in the query tree can be expanded or collapsed as needed. Expanding shown the full details, and allows editing. Collapsing provides a descriptive summary that allows a more compact display of the query.
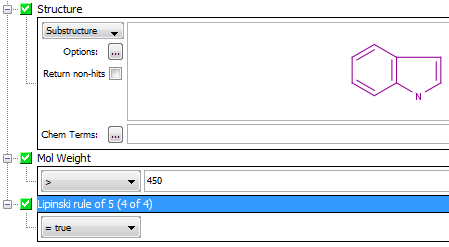

Filtering child data
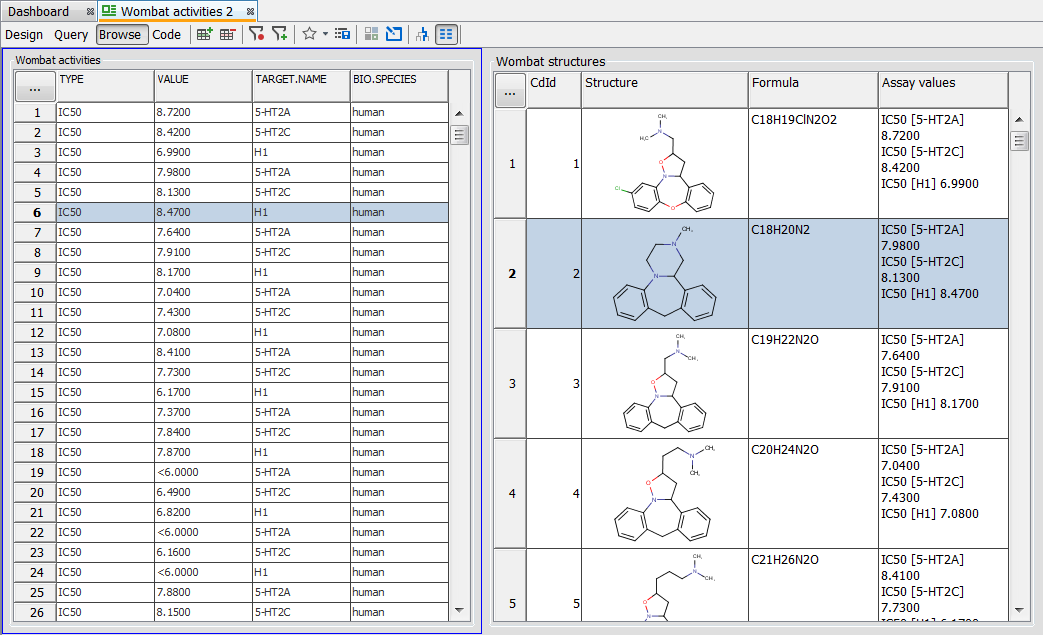
The “Filter search results” feature has been introduced in the 15.10.19.0 release of Instant JChem. It allows for presenting as hits only relevant child data records that fit to the definition set in the query. The icon “Filter search results”, which can be used to turn the filtering on and off, can be found next to the search domain dropdown menu.
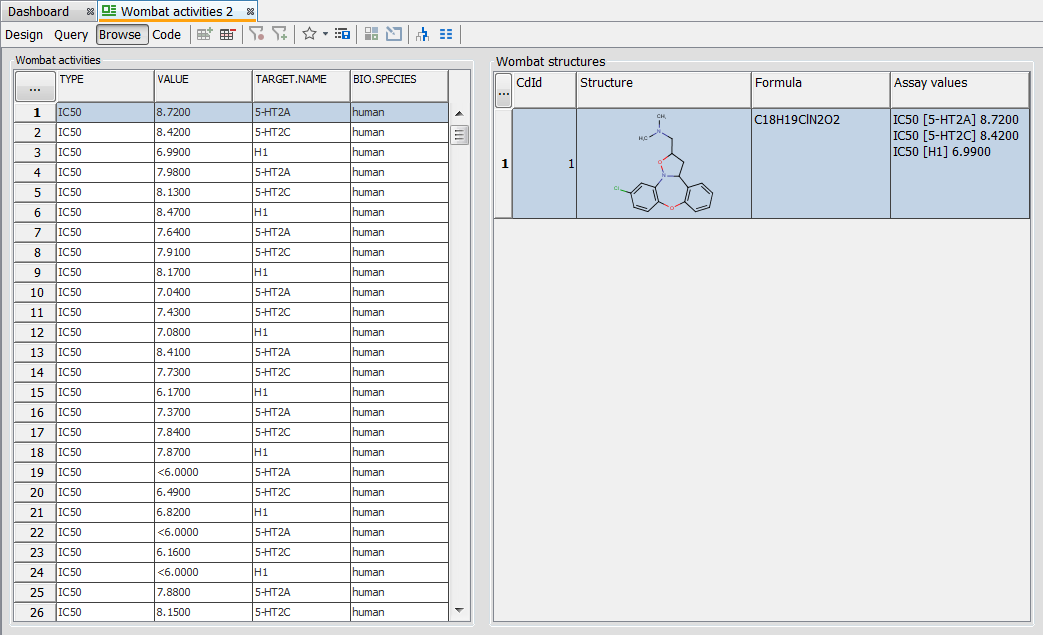
The model query on the Wombat demo data below uses the search for benzene substructure in the Wombat structures entity AND L929 cell in the Wombat activities entity. Without the filter turned on, three records from the Wombat activities table are shown in the hit list, although only one of them contains “L929 cell” value in the BIO.CELL field.
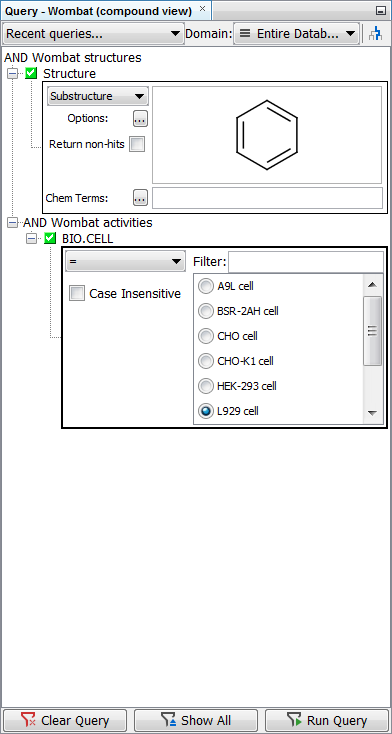
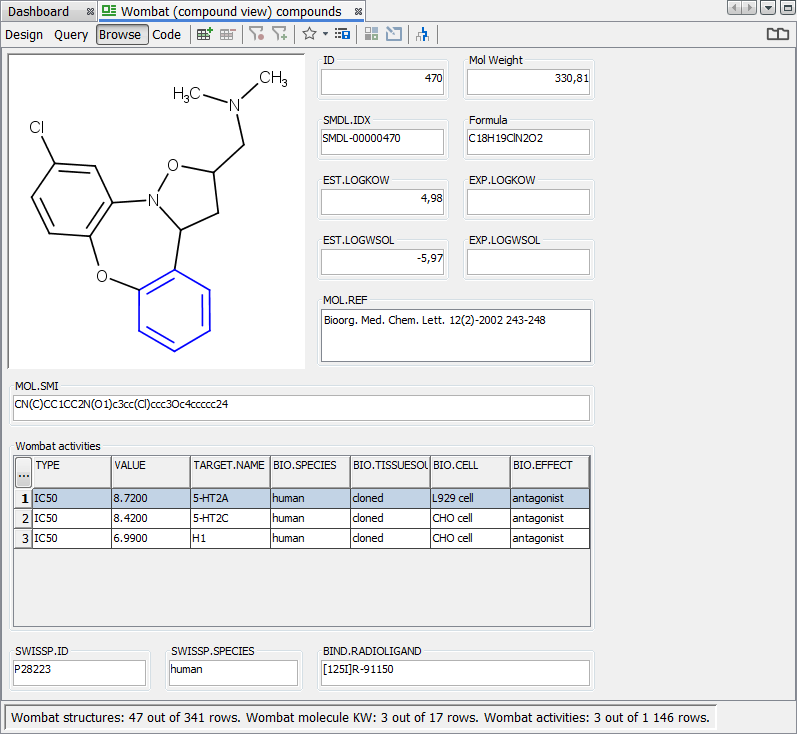
When the search is repeated with the filter turned on, only the record from the Wombat activities table containing “L929 cell” value in the BIO.CELL field is displayed.
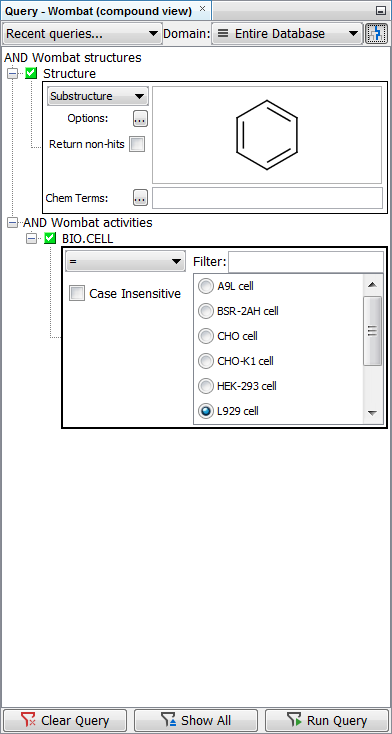
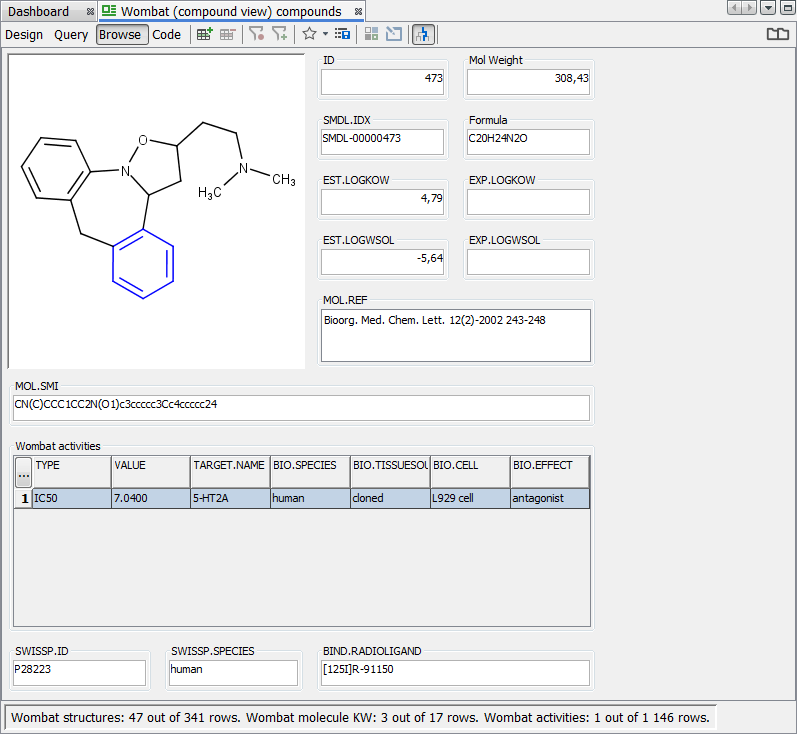
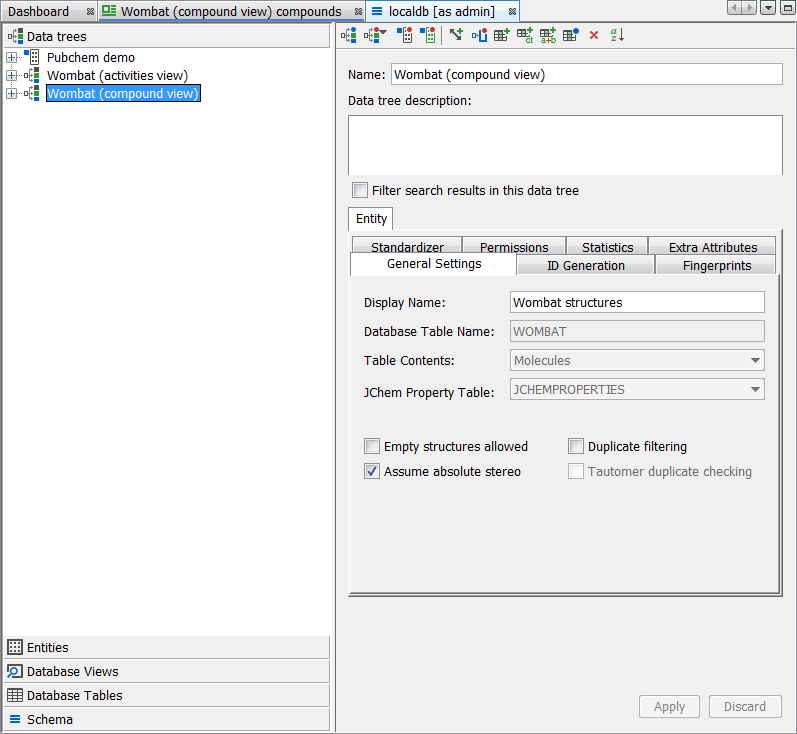
The “Filter search results” feature can be turned on and off globally for each data tree by going to Schema Editor (available through the right-click menu on the schema node). In the Data trees tab, you can select the data tree of interest and select the checkbox Filter search results in this data tree. When selected, all queries in the data tree will have the search results filtered as default. The user can turn the filter off and on only for the present session.
The situation is more complicated when OR operator is introduced in the query. When the OR element is used between fields from the same entity, the filter provides the data in the same manner as with the AND element - the child data are filtered and only relevant data is shown. If the child data had another child data (grandchild data from the parent), all grandchild data for the relevant child data would be listed. Example of such a query in the demo project is shown below.
If the OR element is set between fields originating from different entities, such as parent and child, only the child data fitting to the query definition are shown. For the parent data fitting to the definition, child data will not be shown if they do not match the query definition. Also, grandchild data will not be shown if they do not match the query definition. An example of such a query in the demo project is shown below.
Displaying all convergent data
In the 16.7.25.0 version we have introduced the possibility to display all data in entities bound in convergent (many-to-one or one-to-one) relationship to the parent. When this option is selected, the display options are very similar to Plexus Connect and all the entries are displayed instead of relevant data only. The option can be turned on using  icon present in the view toolbar as well as in the query builder next to the "Filter Search Results" icon. The option can be switched in the view query mode and is taken into consideration only after a new result set is retrieved (e.g. after data query).
icon present in the view toolbar as well as in the query builder next to the "Filter Search Results" icon. The option can be switched in the view query mode and is taken into consideration only after a new result set is retrieved (e.g. after data query).
When the option is turned off, only the result related to the parent data selection is displayed.
When the option is turned on, all the convergent data is displayed and the selection on the convergent data is focused based on the parent data selection.
The selection is inherited only in the parent-child direction. Changing the selection on the child level does not affect the parent data selection.
It is possible to save the default preference for each data tree in the Schema Editor, Data trees tab, similarly to filtering search results preference.
Search domains
Queries can be executed against specific search domains. A domain can be the entire source database or a subset or list results of a previously executed query. A domain can be set by selecting from the drop down box of recently available domains in the data tree.
To execute a specific search against a previously executed query, open the 'Domain' drop-down menu and select a list of results to run new query against. The results of previously executed queries can be identified by their time of execution. The 'Current result' menu item always accesses the last query results.
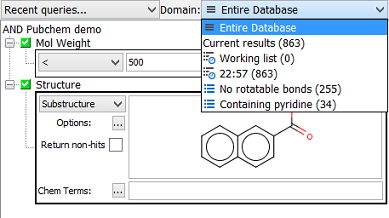
To access different query results, select the list of results in the 'Domain' drop-down menu and click 'Show All' button. Before the results are displayed, you will be asked if you want to keep or clear the query settings (behavior can be set up in Preferences). This will only clear the current query settings. To recall the query settings, all previously used settings can be accessed via 'Recent queries...' drop-down menu.
In future IJC will support other types of constructs such as Field operator Field e.g. Assay1_IC50 < Assay2_IC50.