Overview
The general registration process is as follows. The data needed for chemical registration process (structure, external IDs, salt/solvate info, etc.) are submitted to the Compound Registration. Everything goes through a comprehensive checking process shown in figure Overview 1, which i ncludes validation, standardization, structure checking (and appropriate auto fixing) and structure matching steps.
The first step is a customizable standardization, which is followed by structure checker steps.
-
Some of the checkers serve only as quality checks. The quality checks are defined for the whole database and contain error checkers optionally combined with auto-fixers. It is possible to define on source level by a system switcher if the quality checks should run or not.
-
Other checkers can call selectable structure fixers (e.g. to change bond types or enhanced stereo information according to the business logic). This set can be separately defined for every source.
In case of any checker alert that cannot be fixed or is not set to be fixed automatically, the submission falls into the staging area.
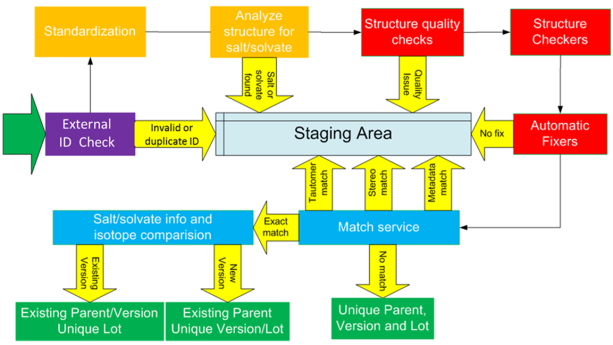
Figure Overview 1. Process of the compound registration
If there is no issue found, then Registration ID is generated. The ID generation process is based on matches of the incoming structure with already registered structures. After the proper treatment of the structure matches, the new compound is registered into the 3-level hierarchy of the registry.
-
Parent - The neutralized (if possible), non-isotopic structure, without any salt/solvate info. Compound Registration ID will be generated on this level.
-
Version - The isotopic/charged version, including the salt/solvate info as well. A different isotopic form and/or different salt/solvate info is considered as a new version (the specification of allowed multiplicities is needed). The role of a version is the grouping of the preparations that share the very same chemical structure of a certain parent – including salts, charges and isotopes.
-
Preparation - The preparation related info, like notebook reference number or lot reference ID.
During the registration, if the parent is unique, then unique corporate registration IDs (PCN, CN and LN) are generated. If only the version was unique, then only CN and LN are generated, and if even the version structure is a duplicate, then only a new preparation with generated LN will be inserted under the same version.
If any issues found during the autoregistration process, the compound falls into the staging area with the appropriate error status. Users with corresponding privileges (e.g. registrars) can pick up failed submissions, fix them either one by one, or if multiple submissions can be fixed by changing the system switcher and structure checker/fixer settings, then fix them in bulk correction mode. After the molecular structure of a submission is drawn or corrected, the changes can be saved, and – based on user/role settings - another person (e.g. a registrar) can review and register it.
During the manual registration process (from the staging area), the validation, standardization and structure checker/ fixer steps are applied on the structure to be registered, then the matches are displayed (exact, stereochemical and tautomer matches), and different options are provided: Accept (register the lot under the same tree, and keep the structures stored in the registry), Replace (register the lot under the same tree, but replace the structure of the compound and all its versions with the new structure) or Register as Unique. A kind of mock registration is also available in the staging area using the "Check" option, which takes the compound through all registration related conversions, and displays any match to compounds already in the registry.
The structures are registered into a "tautomer" JChem table, which makes finding a tautomer match very fast. If a compound is found to be the tautomer of another one already registered, the system can force the new structure to fall into the staging area – depending on the configuration settings –, where the chemist or other privileged user can pick it up and Accept that the new structure, if is the same as its tautomer match (can also choose to Replace the old structure in the registry with the new one at the same time), or choose Register as Unique, if it is a unique compound. A very similar method is used for stereochemical matches, where the Accept/Replace/Unique options are available, too. It is defined in the configuration settings of each source (where source means the origin of the structure that has to be registered, e.g. the ELNB or the Bulk registration), if it is enabled to automatically register tautomer or stereochemical matches, or force them to the staging area.
There is an option to register a preparation directly under a version specified by its CN. In this case, the entered molecule structure is neglected, and only the preparation (lot) related info is registered as a new preparation under the version.
If a difference between two compounds cannot be described in their molecular structure, the Chemically Significant Text (CST) field can be used to provide an additional data, which forces the structure to be unique. It is very useful in case of registering compounds with no structural information (yet), or if the privileged user wants to register the same structure under a different registration ID.
ChemAxon Compound Registration does support three types of multi-component structures. These are referred as alternates, mixtures and formulations. Alternate means that the structure is one of the several drawn structures, but it is not known which one. Mixture composition is represented by %-ranges, while formulations have exact composition information.
Compound Registration supports also Markush structures. "Small" Markush libraries can be registered successfully, as all the other additional chemical databases using JChem can certainly support Markush structures. The list of supported Markush features include R-groups, link nodes, atom lists, position variation, repeating units with repetition ranges, homology groups.
Successfully registered compounds are stored in the
registry
, and a downstream service can transfer them to other corporate database(s), incorporating additional data as required. As it is already described above, it is possible to have a corporate database, where the compound registry related data is stored in dedicated tables (read-only for a normal user), while additional data is stored in other data tables.
Privileged users can amend (modify) any compound or its related data in the registry using the Details page of the Compound Registration web client. All amendment steps are audited, and the complete history of changes is available for each entity, from any level of the
tree
.
External IDs or alternative names can be stored in synonym tables; synonyms can be specified on each (parent, version and lot) level. User management can use the company's central LDAP/AD system (if exists), or its own integrated user management. In both cases the roles can be customized in order to access only specific parts of the registry and to do only limited actions (e.g. a specific user group cannot register from the staging area, or cannot create a new version of the same tree).