Calculated Fields
Table of Contents
Calculated Fields
Calculated fields are fields whose values are calculated from the value(s) of other field(s) and possibly external sources.
IJC also has three other types of field:
-
Standard Fields (for normal data)
-
Chemical Terms Fields (for structure based predictions)
-
URL Fields (for incorporating data located outside IJC)
Purpose of calculated fields
Calculated fields allow calculations to be performed on data from other fields. A simple example would be to calculate the sum of two fields (e.g. "A + B" like calculations) though more complex calculations such as averaging values from a different table, or even accessing data from outside IJC are potentially possible.
We have tried to ensure that creating simple calculations is simple, but that you have the flexibility to generate much more complex calculations if you need. This is done by the calculation being a script that is evaluated, so in effect it is a program that can be used to do whatever you want. However for simple calculations such as the A + B example mentioned above, the syntax to use can be as simple as A + B.
How calculations are performed?
As mentioned above, calculations are in fact scripts that are executed. The language for the scripts is Groovy , a dynamic programming language that is closely linked to the Java language that most of IJC is written in. Groovy provides a powerful programming environment, but also a simple syntax that allows calculations to be defined in a way that looks very natural. Look at the documentation on the Groovy web site for more details. There are also some books available. For advanced usage you definitely need to understand Groovy, but for simple cases you should just be able to follow the examples described here.
Where calculations are performed?
Calculations are performed in IJC itself, not in the database. Results of the calculation are not stored in the database, but calculated dynamically as they're needed. In contrast to older IJC versions (6.3.x and older), where searching and sorting of calculated fields was not possible, current IJC versions are able to perform both search as well as sorting of data based on calculated values. Due to the mechanism used, there is a performance penalty when searching/sorting calculated fields -- the data have to be calculated before the search/sort takes place. However, calculated values are cached so subsequest search/sort will be faster.
How values are provided to the script?
Let's start with a simple A + B example. You have two fields in your entity and want to add a new field that is the sum of the values of those two fields. To do this you specify the two fields in step 2 and specify that the variable names are A and B. Then when the calculation is performed these two variables are magically created in the script context and can be used in the script. So you can write a script that uses these. And really, the script can just be:
A + BIts that simple (but see more below).
In testing your test variables are injected as the values for A and B, whilst when running the actual values for your two fields are injected for each row you are calculating.
What is happening is that Groovy is executing the script "A + B" and A has the value of your first field and B the value of the second field. The script could be as simple as "A + B" or it could be hundreds of lines of Groovy code.
Are the results always up to date?
We hope so, but if you are not sure use 'Data' -> 'Reload data' to be sure. This will force the calculations to be re-run.
What about values from other tables?
Values for fields from other tables (IJC entities) can also be specified, and this really demonstrates the power of calculated fields in IJC. But you might wonder how this works, particularly in the case of one-to-many relationships when there will be multiple values for a field in the other table. You might want to generate a summary of these values (e.g. the average value), or to combine values from multiple fields into a single result (e.g. conditionally averaging values from one field based on the value of another field from that entity). All of this is possible, and much more. You can define how these values are passed to the script. To do this you use the options in the 'Type' column of the variables table. The default is single, which means that just a single value will be passed. In the case of a field having multiple values you can choose to pass the values as LIST in which case all values will be passed (as a Java List object). Alternatively the multiple values can be converted to a single value and passed using one of the other options, SUM, AVG, STR_CAT, which generate the sum, average and comma separated string of the values accordingly. All of those operations could also be performed by the script if you passed the value as LIST. In the simple case you can just use one of these functions e.g. use the SUM function and then the script will just receive a value for that variable that is the sum of those values.
How are values returned from the script?
Groovy has a nice trick that the last statement is automatically returned as the result. So in the case of "A + B" it is the result of that addition that is returned, which is exactly what you want in this case. However in some cases this may not suffice. If so then you can provide an explicit return value like this:
C = A + B
return CIf you are not seeing the results you expect try adding a "return X" statement as the last line.
How do I handle structures?
The structure field can be used a script variable. The data type is the Structure.java IJC class. The key thing you will probably want to do with it is to get the structure in either its original format (e.g. smiles, SDF...) or as chemaxon.struct.Molecule object. Here are examples of each (both assume the structure field is defined as the 'mol' variable.
1. As the original format. Here we are calling the getEncodedMol() method of the Structure class.
mol.encodedMol2. As a Marvin Molecule object. Here we are calling the getNative() method of the Structure class to obtain the Molecule object, and then calling the toFormat() method on the Molecule. You can do much more with the Molecule using the Marvin API.
def m = mol.native
m.toFormat("smiles") // convert to smilesIn both these cases a text value is generated (e.g. you would be using a calculated text field). To display this as a structure you can use the structure renderer in the grid view or the molecule widget in the form view.
For more information see these links:
What about errors?
Your script might generate errors. It may be a bad script and fail for every execution, or it might fail in some specific cases e.g. divide by zero errors, or errors resulting from missing values. Because of this you must test you expression before it can be saved, so that at least we know the syntax is valid. If errors do occur then they are consumed and the result will be null (empty). If you see empty results then it could be because of errors from the script for particular values. Null (missing) values are a particular cause of this, and you can guard for this in your script (but see below on the helper functions) or you can specifically catch errors in your script using
try ... catch ... blocks, but this is too advanced for this guide and you should consult the Groovy docs for details.
Helper functions
There is a hidden "gotcha" in the "A + B" example. Whilst it works fine when values are defined for A and B, the script will cause an error when either A or B are null (missing values). Although these errors will be handled and you will end up with empty values, this is not an ideal solution. So to handle this we provide some "helper" functions in the script that make things easier. Theses are functions like sum(), minus(), multiply(), divide(), avg(), concat() that can be used to simplify writing functions that are more error tolerant. A full list is described in the following table. But as a simple example you could better replace your
A + Bscript with
sum(A, B)and instead of using the AVG function to average your values that are passed to the script, you could instead pass as LIST and then do the averaging like this:
avg(A)|
Function |
Description |
Examples |
|
sum() |
Adds numbers or lists of numbers |
sum(2, 3, 4) // equals 9 sum(a, b) // a and b are variables containing numbers sum(c) // c is a list containing numbers |
|
multiply() |
Multiplies numbers or lists of numbers |
multiply(2, 3, 4) // equals 24 multiply(a, b) // a and b are variables containing numbers multiply(c) // c is a list containing numbers |
|
minus() |
Subtracts the second number from the first |
minus(43, 22) // equals 21 minus(a, b) // a and b are variables containing numbers |
|
divide() |
Divides the first number by the second |
divide(44, 11) // equals 4 divide(a, b) // a and b are variables containing numbers |
|
avg() |
Calculates the average of numbers. Null values are ignored. |
avg(2, 3, 4) // equals 3 avg(a, b) // a and b are variables containing numbers avg(c) // c is a list containing numbers |
|
concat() |
Joins values with the specified characters. |
concat(":", 1, 2) // equals "1:2" concat("\n", a, b) // joins the a and b variables with the newline character concat(",", c) // joins the list of values in the c variable with a comma |
|
each() |
Coordinated looping through 2 or 3 lists. |
each(a, b) \{ x, y -> // do something with x and y// x and y will be a\[0\] and b\[0\] for first iteration// x and y will be a\[1\] and b\[1\] for next iteration// etc. until one of the lists runs out of values\}each(a, b, c) \{ x, y, z -> // do something with x, y and z \} |
In the examples in this table the // character indicates the start of a comment. This and the text to the right of it does not form part of the function, its just there to help describe it. The detailed javadoc for a java class implementing the above functions can be found here .
Note also that there is comprehensive support from the scripting language itself for all sorts of operations. e.g. the java.lang.Math class provides a wide range of mathematical operations, including logarithm, trigonometry and other functions. e.g. to generate the base 10 logarithm of a variable x use:
Math.log10(x)
We welcome suggestions for additional helper functions.
To add a new calculated field:
A new calculated field can be added by any of these methods:
-
In the Schema Editor
-
Using the new calculated field icon in the toolbar (
 )
) -
Using the appropriate item in the popup menu that appears when you right click on an entity, or other appropriate places.
-
-
Using the 'New Calculated Field...' item from the Data menu
-
In the Grid View
-
In Design mode of the Form View
Starting to create other fields is also done in similar way as calculated fields. See the documentation for standard fields for full details.
Step 1. Specify field type:
Specify the type of field (Integer, Text etc.) from the first combo box. This is the type of value for the calculation result.
Step 2. Specify the required fields:
Click on the 'Add' button and specify the fields the calculation depends upon. For each row of the table the calculation will be performed as needed, and the values for these required rows will be "injected" into the calculation as named variables, so that those variables are available for evaluation. You can also specify the entity the field comes from. The default is a set of fields from the entity to which you are adding the calculated field, but you can also choose any entity that has a relationship to that entity.
You can specify the name of the variable for the selected field (a default is generated for you based on the name of the field). This is the variable name in the script that will contain the actual value to be used.
You can also specify how the value(s) for the field are to be presented to the calculation. See above for more details of this.
A value for testing can also be specified. Again a default is provided but you can specify different ones to be sure that your calculation is giving the expected results.
Do this for each of the fields your calculation is going to use.
Step 3. Specify the expression for the calculation:
Enter the expression for the calculation. See below for examples.
Step 4. Test the calculation:
Check that the calculation works as expected using the 'Validate' button. You might need to change the test variables to run a more meaningful test. This lets you check that the expression is valid and that you get the expected results.
Step 5. Create the calculated field:
Click on the OK button to add the calculated field.
To edit an existing calculated field:
The expression for a calculated field can be updated, either in the schema editor or in the widget customiser in the form or grid view. The process is much the same as the later steps of creating a new field so won't be repeated here.
Examples
The best way to illustrate all this is with some real examples. So load up the demo project data and look through these examples.
These examples provide guides to how you can use calculated fields. They use the demo data that comes with IJC so that they can be easily followed. They are not necessarily meaningful calculations and you not doubt will have more meaningful ones to apply to your own data.
1. Simple A * 1000 example
Here we will start with the most simple example: take the value of a field and multiply it by 1000. This could be useful for converting units. e.g. grams into milligrams. In our example we will multiply the molecular weight of the Pubchem demo structures by 1000.
-
Open the pubchem grid view.
-
Click on the 'New calculated field' icon in the grid view toolbar. The dialog will open.
-
Select 'Calculated Decimal Number Field' as the type of field, as the results of our calculation will be a decimal number.
-
Enter "MW * 1000" as the field name.
-
Click on the 'Add' button and select the 'Mol Weight' field.
-
Enter "molWeight * 1000" as the expression.
-
Click 'Validate' and you should see the result of 1000.0. This is correct because the default test value is 1.0.
-
Enter 123.45 as a more meaningful test value and check you get the right answer.
-
Click OK and the calculated field will be added to the grid view and you will see the results of the calculations.
OK, so that was pretty simple. But actually its not ideal as the calculation is subject to errors resulting from missing values. If for some reason the molecular weight is undefined (e.g. the molecule contains list atoms) then the calculation would fail for those, and although the error would be handled and the result would be empty as expected its not the best approach. A better approach would be to use the multiply() helper function to do the calculation as that correctly handles null values (null values are ignored in multiplication). So to do this edit the field definition and change the calculation to "multiply(molWeight, 1000)"
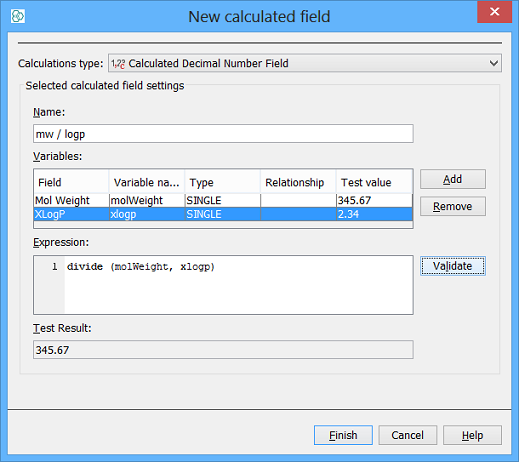
2. Simple A / B example
Here we use two fields in a calculation. Still it is a pretty simple calculation and very simple to perform. We won't repeat the steps in detail from now on, just the key aspects. In this example we will divide the molecular weight by the XLogP value.
-
Add the field as before and add the Mol Weight and XLog P fields as variables.
-
Enter "divide(molWeight, xLogP)" as the expression (assuming you did not rename the variables).
-
Validate and add the field.
3. Using values from different table
Here we will switch to the Wombat demo data and add a calculated field to the structure entity whose results are a summary of the corresponding rows in the assay table. In this case we will generate the average of the VALUE.MIN field.
-
Create a new form view for the 'Wombat (compound view)' data tree and add two table widgets to the form, one for the structure entity and one for the assay entity. Make sure you are showing the VALUE.MIN and VALUE.MAX fields in the assay table.
-
Switch to browse mode and add a new calculated field to the structure table.
-
Choose 'Calculated Decimal Number Field' as the field type and add the VALUE.MIN field from the assay entity to the variables table. You will probably want to change the variable name. Use 'vmin'.
-
Change the 'Type' to AVG.
-
Enter vmin as the expression (this is necessary as we need to specify what the script should return as its result.
-
Validate the expression and add the field.
4. Using the avg() helper function instead
The last example used the AVG function to average the values BEFORE they are set to the script. Let's see how we could instead have done the averaging in the script. Instead of using AVG as the TYPE chose LIST. This will pass the individual values as a list. For the expression specify "avg(vmin)" This uses the avg() helper function to do the averaging.
5. Doing the averaging ourselves
Now lets look at doing the averaging ourselves as an example of when we need to do the actual work in the script (let's assume that neither of the above approaches could be used and we needed to calculate the average ourselves).
Do as before and add the vmin variable as LIST. Then enter this as your expression:
sum = 0
count = 0
vmin.each {
sum += it
count++
}
return count ? sum / count : 0OK, so at last we have something that looks like a program. You would only need to do this for more advanced calculations, so you may want to ignore this, at least until you are more comfortable with the simpler calculations. But lets look at this example briefly:
|
This initialises two variables that we will use to record the running total and the number of values |
|
This iterates through the item in the vmin list using the Groovy each operator |
|
This happens inside the loop and adds the value (exposed as the magical 'it' variable) to the sum and increases the count by 1 |
|
This returns the result, with special handling for the case of having no values to avoid divide by zero errors. |
OK, so that's a little more advanced that we probably need for now, but it begins to show the flexibility that is possible.
6. Generating text summaries
Here we will generate a text field that summarises the values in the assay table. Here we will write out the values from the VALUES.MIN field as a text field, one value per line.
Do as before, and create a 'Calculated Text Field' and add the VALUE field as LIST with the val variable name. Now enter this as the expression:
concat('\n', val)Here we are using the concat() helper function, for which the first argument is the separator to use, '\n' in this case being the newline character. Pretty simple really.
7. Summarising multiple fields.
This is similar to the previous example, other than we will summarise data from two fields, VALUE.MIN and VALUE.MAX. We will use the each() helper function that allows us to loop through multiple lists in coordinated fashion.
As before, create a text field and add VALUE.MIN and VALUE.MAX as the vmin and vmax variables. Now use this as the expression:
res = ""
each(vmin, vmax) { a, b ->
res += concat(' - ', a, b)
res += '\n'
}
return resThe only thing really new here is the each() helper function. You pass it two lists and for each iteration it returns the two values at that position in the list. e.g. First time through the loop you get the first items in the lists, second time through the second items etc. The values are passed in as the a and b variables specified in the
a, b ->part of the expression. the inner part of the loop just combines the values of a and b into the resulting string.
Summary
These examples have hopefully shown how simple calculations can be very simple to perform, but that you also have the capability to perform much more complex "calculations". In fact they don't really have to be calculations at all. They could query a different database or web service to obtain data and make it accessible to IJC. Examples for these sorts of things will be provided later.
We welcome feedback on this feature. Please provide feedback via the Instant JChem forum .