Performing an Overlap Analysis
Background
Instant JChem provides a simple way to look for identical or similar structures in two database tables. This allows you to answer questions like:
-
Which structures in this vendor library are already contained in my own database?
-
What proportion of structures in one database are more than 85% similar to any structures in another database?
To perform an overlap analysis:
-
Create a JChem entity (database table) for each of the sets of structures you wish to analyse. These do not have to be in the same database, but typically are. Here we will assume that you have created two JChem tables, one with the query structures and one with the target structures.
-
Choose Chemistry -> Overlap Analysis. The Overlap Analysis wizard opens.
Step 1: Query and Target selection
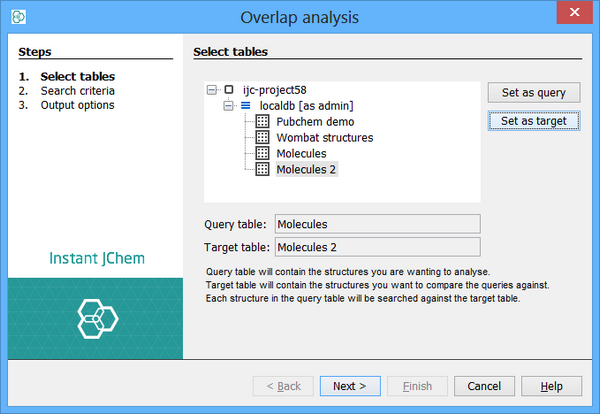
-
Select the query and target tables (these can be the same tables if you want to do a self-comparison), by selecting them from the mini Project Explorer and clicking on the appropriate 'Set as...' button.
Step 2: Search options
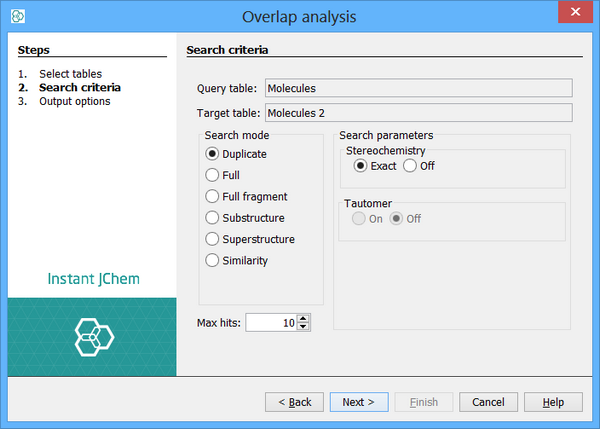
-
Specify the maximum number of hits to report for each query structure (this is most useful when running a similarity search).
-
Specify the type of search (duplicate, full, similarity).
-
Specify search options. These are the same as the structure search options when running a query .
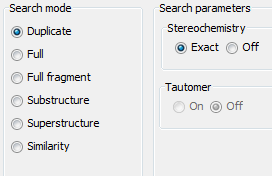
If the target entity is created as type "Query structures" then the tautomer search option will not be available during "duplicate" overlap analysis (both option will be grey out).
If the target entity is created as type "Molecules" without "tautomer duplicate" option ticked then the tautomer search option will not be available during "duplicate" overlap analysis (both option will be grey out).
-
Click Next to move to the next step
Step 3: Output options
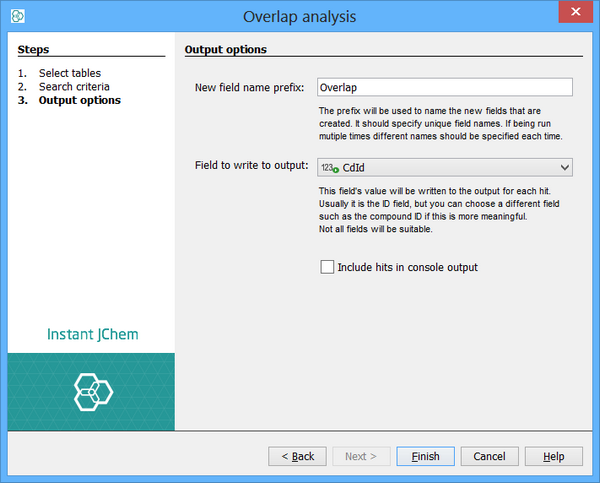
-
Specify a name to use as a prefix for the resulting Fields. When running multiple sets of overlap analysis on the same query table, each one must be provided with a unique name to use as the field prefix.
-
Specify the field in the target table whose values are to be used in the output. Typically this is the ID field which will be selected by default, but if, for instance, your target table also contains a separate compound ID then you might want to specify this field.
Not all fields will be appropriate so choose carefully.
-
Specify whether to write the hits to the console window. Typically this is useful, but it there are a very large number of query structures that match then the output can get too long and you can run into OutOfMemoryErrors.
-
Click 'Finish' to start the analysis. For large numbers of structures this can take some time to complete.
-
A report is written to the Output window, and progress can be followed by looking at the progress monitor in the bottom right corner of the main window:

Results
Fields are added to the query table displaying the results of the search for each structure. The following fields may be added:
-
A field with a count of the number of hits found
-
A field with the highest similarity score (only present when a similarity search is run)
-
A field listing the cd_id values (or whichever field you specified in step 3) of the hits (and the similarity score for each hit if a similarity search was run)
These fields can be sorted and queried like any normal field. This can be very helpful when performing an analysis of the results.