RDF File Import
This document describes the process for importing data from files in MDL's RDF format.
In this context RDF has nothing to do with the more commonly used W3C RDF (Resource Description Framework).
This process can also be used for importing SDF files. Whilst this usually has little benefit compared to using the standard process, it can be of use if you want to create an reproducible process for importing SD files.
About RDF data:
MDL's RDF format is a loosely documented format, and is used for many purposes, primarily for storing reactions and for storing hierarchical data to file. See the CTFile formats documentation for more details about the RDF format. Typically RDF files are generated by exporting data from an ISIS/Host database using a Hview which converts the relational data to a hierarchical representation. When importing into IJC we need to reverse this process, but the problem is that much of the information about the relationships between the different data fields has been lost when converting to a hierarchical representation. For instance, it is not possible to tell whether a relationship between two fields is one-to-many or many-to-many. Therefore to be able to successfully import a RDF file you need to have a good understanding of the data it contains before you start.
Another important feature of RDF files is that in addition to the main structure present at the root of the hierarchy, the format also allows structures to be present as data fields (e.g. as properties of the main structure. An example could be a set of conformers of the main structure). This makes the RDF files difficult to interpret when reading them as text.
IJC's approach to importing RDF files:
The current solution to RDF import should be considered a working prototype that is subject to change as we find out all the intricacies of the ways in which the RDF format is used and find the best solution to all the problems.
As RDF import is much more complex than standard import (e.g. of a SD file) a different approach is needed. When importing a RDF file it may take several attempts to optimise all the settings. This would be very frustrating if you had to go through a graphical wizard each time and re-apply all the settings from your previous attempt, just to make one small change. Because of this RDF import uses a different approach to standard import, and uses a template that defines how the RDF data is to be imported. You make changes to this template and then re-run the import process. This way you can easily make a small change and then re-run the import. Another important advantage of this is that templates can be shared between users, so that for commonly used files (e.g. MDL's MDDR and WDI databases) there is a good likelihood that someone else has already done the hard work of working out how to best import the data. We anticipate setting up a 'contrib' area for these templates.
The current templates are text files that you edit in a text editor (IJC can help you here if you open the template file in IJC).
The syntax of the templates is subject to change, and is not currently documented. Once the details of RDF import are better established it is anticipated that a graphical editor for templates will be created.
In the Project Explorer select the node of the Schema into which you wish to import, or double click on this node to open the schema editor (this is preferable as it lets you see the Entities, Fields and Relationships that the import process creates).
Choose Chemistry -> RDF Import . The wizard will open.
The RDF import wizard operates in 2 modes, 'create template' and 'use template'. The 'use template' mode is the default. To create a new template check the 'Create RDF import template' radio button on step 1 of the wizard.
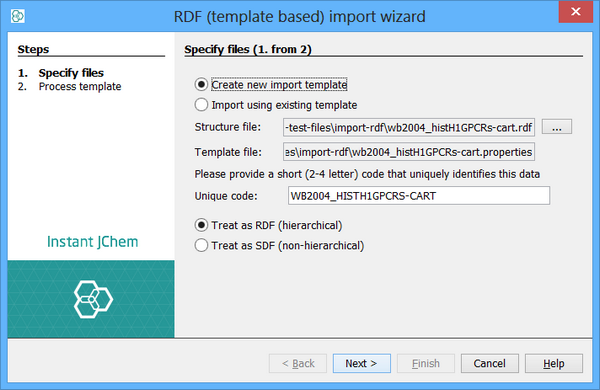
Specify the RDF file that you wish to import in the first file selector. The file name of the template will be automatically generated for you. The name will be the file name of the RDF file, but with a properties extension.
Specify a short (e.g. 2-4 character) unique abbreviation for this dataset. Keep this abbreviation as short as possible as it will form part of the names of the database tables and other artifacts, and these have limits to their lengths. For instance if you are importing the Wombat file you might choose WMBT. This abbreviation is used as part of the names of the database artifacts to ensure that they unique between different datasets (RDF files often use the same naming conventions, so that without this there is the risk that names might conflict between data sets).
Specify the type of file (RDF or SDF). This is usually determined correctly from the file extension. This defines how the file is processed and must be specified correctly.
Click the 'Next' button.
In the next step the whole RDF file will be read and the fields it contains checked so that the best type can be used in IJC. When you see the 'Click Finish to create the template' message you can click 'Finish' and the template will be created.
The RDF import template that is generated may need editing before it should be used. Common operations include:
-
Renaming items to more friendly names.
-
Deleting unwanted items (e.g. if you did not want to import some data, or the import process cannot handle it).
-
Altering field and entity settings (e.g. specifying that a certain data field should be imported as an integer field).
-
Performing substitutions on the data values (e.g. to remove line end characters artificially added to the RDF file).
-
Mapping an item in the hierarchy to a different element (e.g. flattening out the hierarchy). Typically entries in the template are defined a name=value pairs. The syntax should make some sense when you look at a template. The format of the template is subject to change. Please ask on the IJC forum for more information on the exact syntax.
To actually import a RDF file re-run the wizard, this time leaving the 'Import using existing template' radio button checked. Specify the RDF file and click 'Next'.
The import process will commence and you will see the messages about all the IJC artifacts that are created. Then the data import will start. When complete click 'Finish'. A new Data Tree will be created for the item at the root of the RDF hierarchy. Add a new view to this Data Tree (a Form View is most useful). Create a new view for the Data Tree that has been created and use it to inspect the data that has been imported. You will need to design the form to show the appropriate fields. Do not spend too much time on the form design until you are satisfied with the import process.
It is probable that you will see improvements that can be made to the way the data was imported. Iterate back to step 3 and continue until you are happy. Each time you only need to edit the template and re-run it. All IJC artifacts that the template created will be deleted when you re-run (as long as you did not change the entity or table name - if you did then they will need to be manually deleted using the schema editor).
Feedback:
Importing RDF data is a complex process, and each RDF file is different. We welcome feedback on this process, and suggestions for improvements where you come across data that is not optimally handled by the current process. Please provide this feedback through the IJC forum.